Теоретические основы сжатия данных
Характерной особенностью большинства «классических» типов данных, с которыми традиционно работают люди, является определенная избыточность. Степень избыточности зависит от типа данных. Например, у видеоданных степень избыточности обычно в несколько раз больше, чем у графических данных, а степень избыточности графических данных в несколько раз больше, чем текстовых. Кроме того, степень избыточности данных зависит от принятой системы кодирования. Так, например, можно сказать, что кодирование текстовой информации средствами русского языка (с использованием русской азбуки) дает в среднем избыточность на 20-30% больше, чем кодирование адекватной информации средствами английского языка.
Для человека избыточность информации нередко связана с представлением о ее качестве, поскольку избыточность, как правило, улучшает восприятие, особенно в неблагоприятных условиях (просмотр телепередач при наличии помех, восстановление поврежденного графического материала, чтение текстов в условиях недостаточной освещенности и т. п.).
При обработке информации избыточность также играет важную роль. Так, например, при преобразовании или селекции информации избыточность используют для повышения ее качества (репрезентативности, актуальности, адекватности и т. п.). Однако, когда речь заходит не об обработке, а о хранении готовых документов или их передаче, то избыточность можно уменьшить, что дает эффект сжатия данных.
Если методы сжатия информации применяют к готовым документам, то нередко термин сжатие данных подменяют термином архивация данных, а программные средства, выполняющие эти операции, называют архиваторами.
Объекты сжатия
В зависимости от того, в каком объекте размещены данные, подвергаемые сжатию, различают:
• уплотнение (архивацию) файлов;
• уплотнение (архивацию) папок;
• уплотнение дисков.
Уплотнение файлов применяют для уменьшения их размеров при подготовке к передаче по каналам электронных сетей или к транспортировке на внешнем носителе малой емкости, например на гибком диске.
Уплотнение папок используют как средство архивации данных перед длительным хранением, в частности, при резервном копировании.
Уплотнение дисков служит целям повышения эффективности использования их рабочего пространства и, как правило, применяется к дискам, имеющим недостаточную емкость.
Обратимость сжатия
Несмотря на изобилие алгоритмов сжатия данных, теоретически есть только три способа уменьшения их избыточности. Это либо изменение содержания данных, либо изменение их структуры, либо и то и другое вместе.
Если при сжатии данных происходит изменение их содержания, метод сжатия необратим и при восстановлении данных из сжатого файла не происходит полного восстановления исходной последовательности. Такие методы называют также методами сжатия с регулируемой потерей информации. Они применимы только для тех типов данных, для которых формальная утрата части содержания не приводит к значительному снижению потребительских свойств. В первую очередь, это относится к мультимедийным данным: видеорядам, музыкальным записям, звукозаписям и рисункам. Методы сжатия с потерей информации обычно обеспечивают гораздо более высокую степень сжатия, чем обратимые методы, но их нельзя применять к текстовым документам, базам данных и, тем более, к программному коду. Характерными форматами сжатия с потерей информации являются:
• JPG для графических данных;
• .MPG для видеоданных;
• . М РЗ для звуковых данных.
Если при сжатии данных происходит только изменение их структуры, то метод сжатия обратим. Из результирующего кода можно восстановить исходный массив путем применения обратного метода. Обратимые методы применяют для сжатия любых типов данных. Характерными форматами сжатия без потери информации являются:
• .GIF, TIP,. PCX и многие другие для графических данных;
• .AVI для видеоданных;
• .ZIP, .ARJ, .BAR, .LZH, .LH, .CAB и многие другие для любых типов данных.
Алгоритмы обратимых методов
При исследовании методов сжатия данных следует иметь в виду существование следующих доказанных теорем.
1. Для любой последовательности данных существует теоретический предел сжатия, который не может быть превышен без потери части информации.
2. Для любого алгоритма сжатия можно указать такую последовательность данных, для которой он обеспечит лучшую степень сжатия, чем другие методы.
3. Для любого алгоритма сжатия можно указать такую последовательность данных, для которой данный алгоритм вообще не позволит получить сжатия.
Таким образом, обсуждая различные методы сжатия, следует иметь в виду, что наивысшую эффективность они демонстрируют для данных разных типов и разных объемов.
Существует достаточно много обратимых методов сжатия данных, однако в их основе лежит сравнительно небольшое количество теоретических алгоритмов, представленных в таблице 14.1.
Таблица 14.1.
Свойства алгоритмов сжатия
|
Алгоритм |
Выходная структура |
Сфера применения |
Примечание |
|
RLE (Run-Length Encoding |
Список (вектор данных) |
Графические данные |
Эффективность алгоритма не зависит от объема данных |
|
KWE (Keyword Encoding) |
Таблица данных (словарь) |
Текстовые данные |
Эффективен для массивов большого объема |
|
Алгоритм Хафмана |
Иерархическая структура (дерево кодировки) |
Любые данные |
Эффективен для массивов большого объема |
Алгоритм RLE
В основу алгоритмов RLE положен принцип выявления повторяющихся последовательностей данных и замены их простой структурой, в которой указывается код данных и коэффициент повтора.
Например, для последовательности: 0; 0; 0; 127; 127; 0; 255; 255; 255; 255 (всего 10 байтов) образуется следующий вектор:
|
Значение |
Коэффициент повтора |
|
0 |
3 |
|
127 |
2 |
|
0 |
1 |
|
255 |
4 |
0; 3; 127; 2; 0; 1; 255; 4 (всего 8 байтов). В данном примере коэффициент сжатия равен 8/10 (80 %).
Программные реализации алгоритмов RLE отличаются простотой, высокой скоростью работы, но в среднем обеспечивают недостаточное сжатие.
Наилучшими объектами для данного алгоритма являются графические файлы, в которых большие одноцветные участки изображения кодируются длинными последовательностями одинаковых байтов. Этот метод также может давать заметный выигрыш на некоторых типах файлов баз данных, имеющих таблицы с фиксированной длиной полей. Для текстовых данных методы RLE, как правило, неэффективны.
Алгоритм KWE
В основу алгоритмов кодирования по ключевым словам (Keyword Encoding) положено кодирование лексических единиц исходного документа группами байтов фиксированной длины. Примером лексической единицы может служить слово (последовательность символов, справа и слева ограниченная пробелами или символами конца абзаца). Результат кодирования сводится в таблицу, которая прикладывается к результирующему коду и представляет собой словарь. Обычно для англоязычных текстов принято использовать двухбайтную кодировку слов. Образующиеся при этом пары байтов называют токенами.
Эффективность данного метода существенно зависит от длины документа, поскольку из-за необходимости прикладывать к архиву словарь длина кратких документов не только не уменьшается, но даже возрастает.
Данный алгоритм наиболее эффективен для англоязычных текстовых документов и файлов баз данных. Для русскоязычных документов, отличающихся увеличенной длиной слов и большим количеством приставок, суффиксов и окончаний, не всегда удается ограничиться двухбайтными токенами, и эффективность метода заметно снижается.
Алгоритм Хафмана
В основе этого алгоритма лежит кодирование не байтами, а битовыми группами.
• Перед началом кодирования производится частотный анализ кода документа и выявляется частота повтора каждого из встречающихся символов.
• Чем чаще встречается тот или иной символ, тем меньшим количеством битов он кодируется (соответственно, чем реже встречается символ, тем длиннее его кодовая битовая последовательность).
• Образующаяся в результате кодирования иерархическая структура приклады вается к сжатому документу в качестве таблицы соответствия.
Пример кодирования символов русского алфавита представлен на рис. 14.1.
Как видно из схемы, представленной на рис. 14.1, используя 16 бит, можно закодировать до 256 различных символов. Однако ничто не мешает использовать и последовательности длиной до 20 бит — тогда можно закодировать до 1024 лексических единиц (это могут быть не символы, а группы символов, слоги и даже слова).
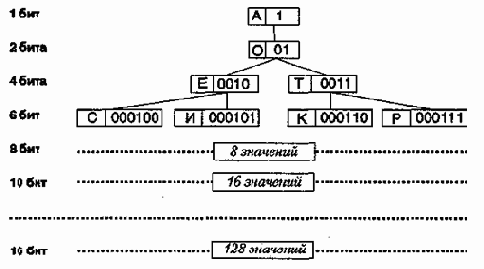
Рис. 14.1. Пример побуквенного кодирования русского алфавита
по алгоритму Хафмана
В связи с тем, что к сжатому архиву необходимо прикладывать таблицу соответствия, на файлах малых размеров алгоритм Хафмана малоэффективен. Практика также показывает, что его эффективность зависит и от заданной предельной длины кода (размера словаря). В среднем, наиболее эффективными оказываются архивы с размером словаря от 512 до!024 единиц (длина кода до 18-20 бит).
Синтетические алгоритмы
Рассмотренные выше алгоритмы в «чистом виде» на практике не применяют из-за того, что эффективность каждого из них сильно зависит от начальных условий. В связи с этим, современные средства архивации данных используют более сложные алгоритмы, основанные на комбинации нескольких теоретических методов. Общим принципом в работе таких «синтетических» алгоритмов является предварительный просмотр и анализ исходных данных для индивидуальной настройки алгоритма на особенности обрабатываемого материала.
